引言:當物聯網遇見大數據
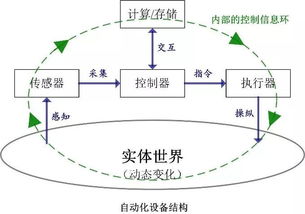
在當今的數字時代,物聯網(IoT)與大數據的交匯正在重塑我們的世界。物聯網,即通過各種信息傳感設備(如RFID、傳感器、GPS等)將萬物連接到互聯網,實現智能化識別、定位、跟蹤、監控和管理。它每時每刻都在產生海量、多樣、高速的數據流。而大數據技術,正是處理、分析和從這些龐雜數據中提取價值的關鍵工具。本章將概述大數據在物聯網服務中的核心角色、技術原理及其帶來的深刻變革。
一、物聯網:大數據的“超級生產者”
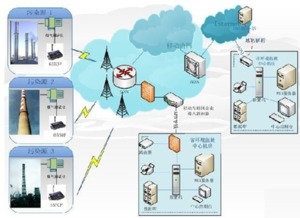
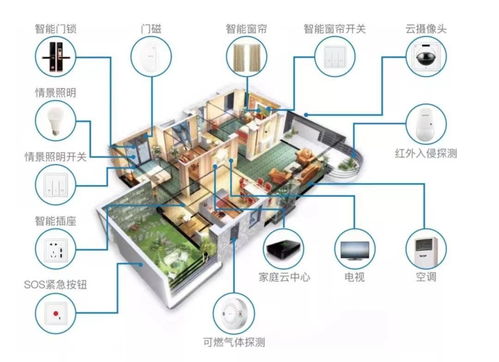
物聯網構成了大數據的核心來源之一。從智能家居中的溫濕度傳感器,到工業生產線上的振動監測儀;從城市街道的交通攝像頭,到可穿戴健康設備,數以百億計的“物”持續不斷地生成數據。這些數據具有典型的“4V”大數據特征:
- 體量巨大(Volume):連接的設備數量呈指數級增長,數據生成速度前所未有。一個智能工廠一天產生的數據可能高達TB甚至PB級別。
- 種類繁多(Variety):數據格式多樣,包括結構化的設備ID、溫度讀數,半結構化的日志文件,以及非結構化的視頻、音頻和圖像流。
- 速度極快(Velocity):許多物聯網應用要求實時或近實時處理,如自動駕駛汽車的傳感器數據、電網故障的即時監測,數據流持續不斷且處理延遲要求極高。
- 價值密度低(Value):原始數據流中蘊含著巨大潛在價值,但單條數據價值可能很低,需要經過深度分析才能提煉出洞察。
二、大數據技術棧:物聯網數據的“處理引擎”
面對物聯網產生的數據洪流,傳統的數據處理技術已力不從心。以Hadoop、Spark等為代表的大數據技術棧提供了從采集到洞察的完整解決方案:
- 數據采集與集成:利用如Apache Kafka、Flume等工具,實時、可靠地攝取來自千萬級設備的海量數據流,解決數據入口問題。
- 數據存儲與管理:采用分布式文件系統(如HDFS)和NoSQL數據庫(如HBase、Cassandra),或時序數據庫(如InfluxDB),以低成本、高可擴展的方式存儲海量異構數據。
- 數據處理與分析:
- 批處理:使用Hadoop MapReduce或Spark對歷史數據進行深度挖掘,用于模式發現、預測性維護建模等。
- 流處理:使用Storm、Spark Streaming或Flink對數據流進行實時處理,實現即時警報、動態定價等。
- 數據挖掘與智能:應用機器學習、深度學習算法(常在Spark MLlib、TensorFlow等框架上運行)對數據進行分析,實現預測、分類和優化,這是將數據轉化為智能服務的核心。
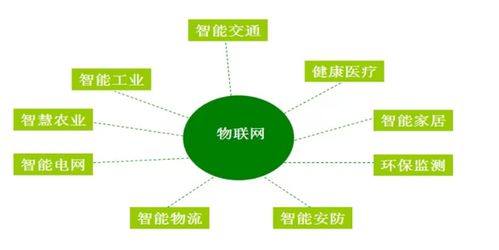
三、物聯網大數據的典型應用場景
大數據技術賦能物聯網,催生了眾多創新服務:
- 智慧城市:分析交通流量、攝像頭和傳感器數據,優化信號燈控制,緩解擁堵;監控能源消耗,實現智能電網。
- 預測性維護:在制造業,通過分析設備傳感器數據流,預測機械故障,提前安排維護,大幅減少停機時間。
- 智能健康:持續收集可穿戴設備的生理數據,通過大數據分析實現個人健康預警、慢性病管理和個性化醫療建議。
- 精準農業:利用部署在田間的傳感器收集土壤、氣候數據,結合大數據分析,指導精準灌溉、施肥,提升產量。
- 車聯網與智能駕駛:處理車輛自身傳感器及路側單元的海量實時數據,用于路徑規劃、碰撞預警和自動駕駛決策。
四、挑戰與展望
盡管前景廣闊,物聯網與大數據的結合也面臨挑戰:數據安全與隱私保護(海量設備成為攻擊入口)、數據質量與一致性(設備異構、數據噪聲)、邊緣計算的興起(為降低延遲和帶寬壓力,部分數據處理向網絡邊緣遷移)以及技術與人才的缺口。
隨著5G的普及和邊緣人工智能的發展,物聯網數據的產生和處理將更加去中心化和智能化。大數據技術將繼續演進,以更高效、更安全的方式,從物聯網的“數據海洋”中挖掘出驅動社會進步和產業升級的“智慧寶藏”。
小結
物聯網是大數據最重要的源頭活水之一,而大數據技術是解鎖物聯網數據價值的必備鑰匙。理解大數據的技術原理,并將其有效地應用于物聯網服務的設計與開發中,是構建下一代智能化應用和服務的基石。從數據洪流到商業洞察,這是一場由技術驅動的深刻變革,而我們正身處其中。